If you compile a C program twice, can the compiler produce two different binaries?
In my current research project, the experiments I run basically consist of compiling some programs with our source-to-source compiler (which sends some parts of the program to the GPU using OpenACC directives), and comparing their running times with their original version. We’re trying to make things faster automatically by using GPUs.
More recently, I’m experimenting with an idea that involves optimizing some numeric parameters that guide our compilation using Simulated Annealing. Basically, we start with some “reasonable” parameters, and try to change them incrementally to see if we can generate faster programs. But then, in order to evaluate a given set of parameters, I need to compile them with those parameters, run them and measure how long it took. With a complete run of all programs usually taking more than half an hour, it quickly becomes impractical to run even a hundred iterations of Simulated Annealing. But there’s something that comes to the rescue.
The fact is that many times, even with different parameters, our compiler will generate the same programs over and over. Not all parameters will affect all programs equally, so if we change them a little bit, let’s say that from our training set of about 20 programs, 2 or 3 of them will be affected. Since these programs are well-behaved, in the sense that they always do the exact same computations every time they are ran with the same parameters, it’s natural to want to cache these results.
So I did. I wrote a Python script that receives an executable and its arguments. Instead of running it directly, it reads the executable file, hashes it along with the arguments, and checks if a local file contains a record with the same hash. If so, it simply prints the average time stored in the file. If not, it runs the program 5 times, saves the result to the file, and prints it.
It worked well for running the original version of the programs. But for some reason the version our compiler generates was being ran over and over. Weird, since the C compiler we use in both cases is the same, pgcc.
Just to check pgcc was not generating two different executables for the same program, which seemed unlikely, I wrote a very simple C program:

Fine. The only difference between this setting and the actual setting was that I was compiling the benchmarks with the “-acc” flag, for pgcc to process OpenACC pragmas. It shouldn’t make any difference in this case since the program is trivial. But just to be sure I gave it a try:

Oh! So with pgcc -acc is non-deterministic, even for programs that have no OpenACC at all! How come? What could be the difference? Well, since the executables are here, let’s check:
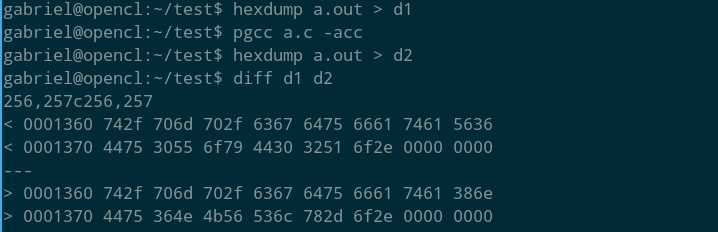
Hmm, so it looks like only a few bytes changed. I have no idea what the changes are, but I guess it could be a timestamp or some other data related to when the compilation was done.
Very nice as a curiosity, but then, I still need to cache the running times of equal programs in order to run Simulated Annealing before the Heat death of the universe (or, more practically, before I run out of scholarships). It would be good if I could just fix these changed bytes to zero if they don’t change the behavior of the program (they shouldn’t, since it’s the same program). But playing with it a bit showed that these bytes don’t always appear at the same place in the executable.
However, where is this data in the executable? If it’s in a debugging information section, I could just run ‘strip’ on the binary to get rid of these data and get identical executables. But it turns out it wasn’t. Here’s where it is:
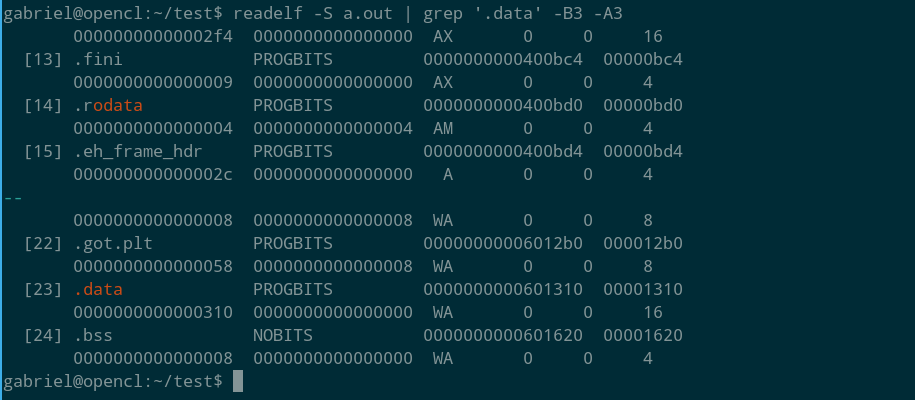
The last column shows where each section begins (its offset). This tells us that the data section goes from offset 0x1310 to offset 0x161F (since the next section, “.bss”, starts at 0x1620). All right, the mutant bytes are in “.data”, then (hexdump told us they’re between 0x1360 and 0x1380).
Quick and dirty solution? Now, instead of hashing the binary, my script runs “objdump -d” to disassemble its executable sections, and hashes that instead. Since the benchmarks I’m using for the Simulated Annealing all run for at least several seconds (and some for minutes), while their binaries are quite small, disassembling is much quicker than running the programs on average. Not the most beautiful caching system ever, I must admit. But at least until now it’s been working :)